基于scrapy的动态网页采集方案总结
Created at 2017-05-12 Updated at 2018-05-16 Category Crawler
基于scrapy的动态网页采集一直是个难点,而且如果想达到工程级别的抓取,需要有个高效率的解决方案。我列出了几个曾经尝试过的方案和它们的特点。
基于PyV8等脚本解析引擎
这类方案的原理是利用开源浏览器项目中的脚本解释引擎,实现相关脚本片段的解析,从而获得动态页面主体内容与超连接网络地址。自行构建脚本环境的方法以JavaScript脚本解析引擎为基础,构造解析动态页面脚本程序片段的环境。由于JavaScript脚本解析引擎只对JavaScript语言的基本对象做了支持,无法解析动态页面嵌入的JavaScript片段所使用的浏览器DOM对象,因而在利用这些脚本解析引擎解析动态页面脚本片段时,需要自己实现DOM对象,使脚本解析引擎支持浏览器DOM对象。
这种方法能够在非web环境下执行独立的Javascript语句,可以细粒度地控制网页中Javascript的执行。但由于实际抓取时缺少web环境,无法对如上图所示的DOM树等对象进行操作,因此这种方案很难适用。
自动化测试工具 + 浏览器
这类方案使用开源浏览器渲染整个动态页面,从浏览器输出结果中提取页面主体内容与超链接网络地址。Selenium是由thought Works公司开发的web自动化测试工具。它直接在浏览器中运行,就像真正的用户在操作一样。Selenium框架底层使用Javascript模拟真实用户对浏览器进行操作。当执测试脚本时,浏览器自动按照做出相应的操作,就仿佛真实用户一样,因而可以从终端用户的角度测试Web应用。下图是在并发数为4,抓取20条URL情况下各浏览器性能对比: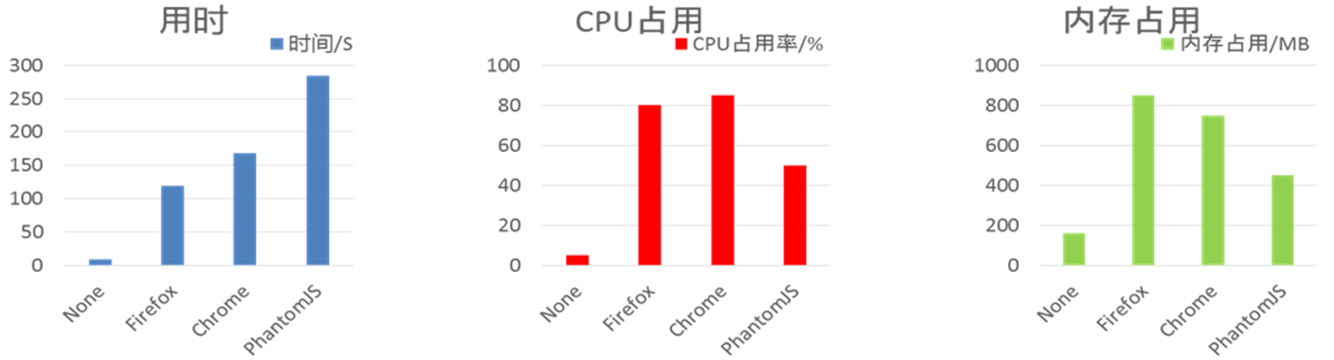
这种方法能够完整得到浏览器渲染过的动态网页源码,但它需要调用外部程序,CPU和内存资源占用较高。由上图可以发现各个浏览器的用时、CPU占用和内存占用对实际应用来说是无法接受的;同时,该方案执行了很多和页面的文本内容和链接无关的脚本片段,针对性不够强,会使得整个系统的性能消耗过大,导致其效率低下,严重影响数据的采集速度。
基于QtWebkit的下载中间件
WebKit 是一个开源的浏览器引擎,相比于其他浏览器引擎来说,Webkit的优势在于高效稳定,兼容性好,且源码结构清晰,易于维护。而QtWebkit是集成了Qt接口的Webkit实现,底层由C++开发,本方案中使用的是该内核的Python封装PyQt。在具体实现中,我们单独构建一个独立的下载中间件,在process_response函数中对网页源码进行动态渲染,并将渲染后得到的HTML代码替换源码。
它能够利用其中的脚本解析引擎执行页面中嵌入的JavaScript脚本程序片段;无需调用外部程序,系统资源占用较小。但这种方案很难适用,因为QtWebkit的调用方法与下载中间件的结构设计无法统一,导致爬虫退出时QtWebkit异常崩溃;下载中间件渲染网页时,其他请求会被阻塞,渲染效率较低。
基于ghost.py的下载中间件
ghost.py是对QtWebkit进一步封装,封装后的调用方法与下载中间件的结构能够较好地结合,解决了爬虫退出时的崩溃问题;同时,ghost.py能够创建DOM对象,构造解析动态页面脚本程序片段的环境,支持单条Javascript语句的执行;在具体实现中,我们仍然构建一个独立的下载中间件,处理返回结果时进行动态渲染,并将渲染后得到的HTML代码替换源码。
这种方法可以细粒度地控制渲染细节,比如禁用图片设置、资源加载超时设置等。但是,下载中间件是处于核心引擎和下载器之间,爬虫运行时只有一个示例对象,这样的系统定位导致网页渲染仍然是阻塞式的,执行效率较低。
基于ghost.py的下载器
改造scrapy的下载器,在下载器中使用ghost.py完成网页源码解压和动态网页渲染的步骤,这种方案的目的是尝试在下载器多线程并发下载的同时能够并发渲染,以期能够提高下载器的抓取效率。关于下载中间件渲染和下载器渲染的系统结构区别如下图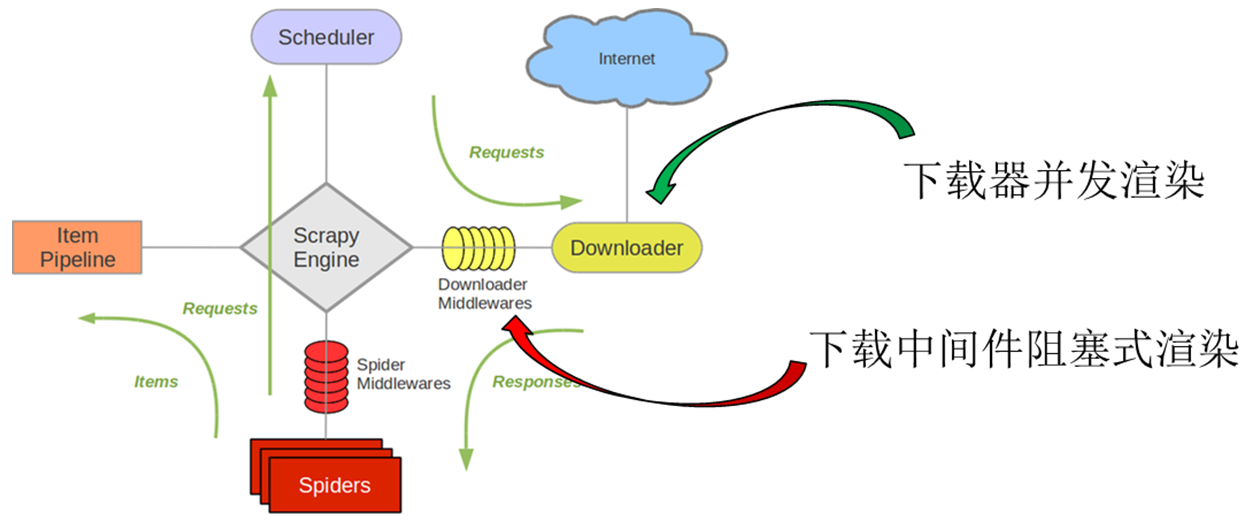
我们的测试结果表明这种方案下爬虫的CPU使用率较低,下载器的线程无法利用多核执行;网络I/O和动态解析等待耗时长,数据抓取效率难以提升。这是因为:Python语言具有全局解释器锁的特性,它的作用在于让同一时刻只能有一个线程对于Python对象进行操作,这使得逻辑上并发的线程物理上仍然是顺序执行的;网页的渲染缺少异步处理的能力,单个线程会被挂起等待,直到渲染结果返回才会唤醒继续执行,这也导致数据抓取效率的降低。
在我们使用ghost.py的过程,我们遇到一个非常棘手的内存段错误的bug,爬虫每次在爬取到几百条URL之后会出现core dump异常并自动结束程序。我们使用dmesg命令检测内核环缓冲,了解系统的启动信息,得到如下的错误信息提示:
我们计算得到libQtWebkit.so.4.8.1中出错函数的相对地址: A1E7F9。然后利用gdb调试反汇编代码,定位到运行出错的机器码如下图:
经过初步分析,我们认为出错发生在程序访问eax地址时,内存读操作越界。该错误出现在QtWebkit中CSS色彩梯度渐变渲染函数内,这应该是PyQt 4.8.1版本中的一个小bug,而修改源代码涉及的工作较为复杂且工程浩大,故也因此舍弃了该方案。
基于splash渲染服务
通过对前面几种技术的分析和测试,我们发现这些方案都存在服务器资源利用效率不高、运行效率低和不稳定性等问题,于是我们考虑引入一种基于splash服务的动态解析方案。splash是基于Twisted异步处理框架和Qt开发框架实现的、对外提供HTTP API的一种网页渲染服务,其中Twisted使渲染服务具有异步处理能力,可以发挥Webkit的并发能力。结合了splash的scrapy系统架构和工作方式如下图: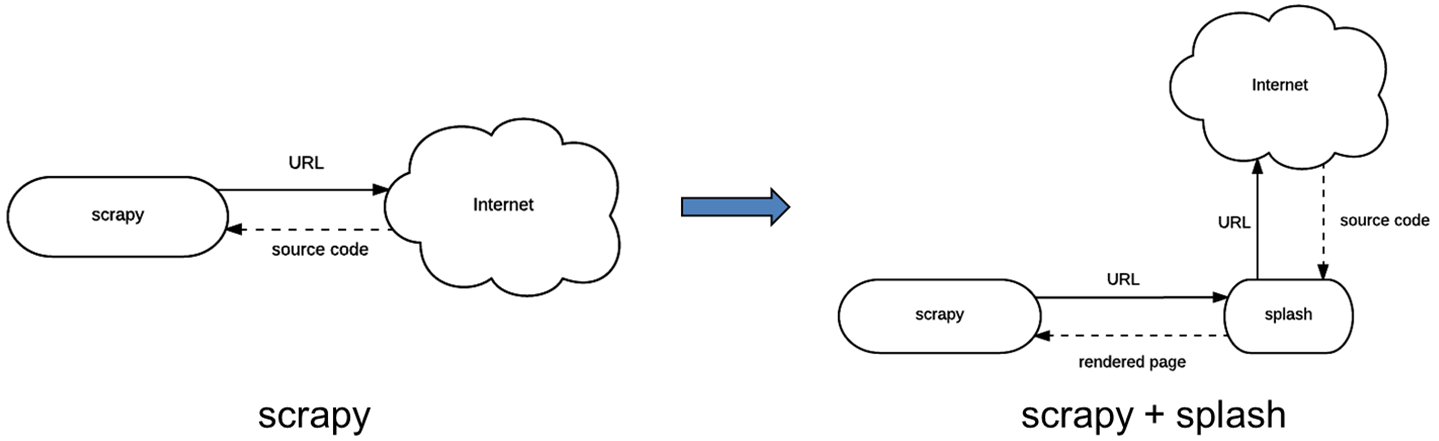
splash的动态渲染服务是我们最终采用的方案,但它在应用时有如下问题:splash的启停和参数设置无法由scrapy控制;splash运行时有极小概率崩溃;splash的endpoint参数设置对抓取效率和内存占用影响较大。
虽然splash内部采用了Twisted异步处理框架,但这种方法只能节省线程等待网络IO和CPU渲染的时间,splash仍然会受困于Python全局解释器锁的限制,无法有效地利用多个CPU内核进行处理。单个splash即使满负荷运行也只能占用一个内核。而且原有方案是一个scrapy进程关联一个splash服务,splash的启停由scrapy单独控制,不与别的scrapy进程共享。这种即时开关splash服务的方法本省会消耗系统宝贵的计算资源,也会给整个爬虫系统的运行带来不稳定性。同时,不同splash服务之间的负载不均衡,也会给系统整体的抓取性能带来损害。
所以,我们利用nginx反向代理服务来实现splash服务的负载均衡。nginx是一款轻量级的、高性能的Web 服务器/反向代理服务器,这里我们将它用作反向代理服务器来实现负载均衡。反向代理方式是指以代理服务器来接受internet上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给internet上请求连接的客户端,此时代理服务器对外就表现为一个反向代理服务器。
nginx可以很容易通过模块扩展,所以nginx所拥有的功能集合也是很大的。nginx中的upstream负载均衡支持下面几种方式:轮询(默认):按照时间顺序对所有服务器一个一个的访问,如果有服务器宕机,会自动剔除;权重:服务器的访问概率和权重成正比,这个可以在服务器配置不均的时候进行配置;IP哈希:对每个请求的IP进行哈希计算,并按照一定的规则分配对应的服务器;公平:按照每台服务器的响应时间来分配请求,响应时间小的优先分配;URL哈希:按照访问URL的哈希值来分配请求。
下面的测试中,我们使用单个scrapy进程进行抓取,一共抓取991条URL,通过nginx反向代理请求不同数量的splash渲染服务,分别在scrapy请求并发数为50、100和150三种情况下进行对比。其中nginx在实现负载均衡时采用了默认的轮训方式。测试结果如下图: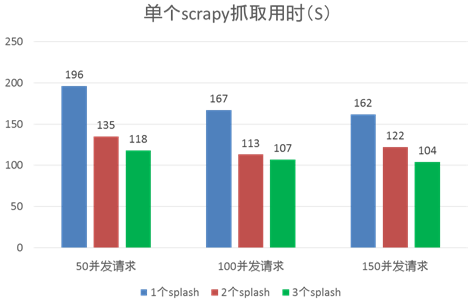
从图中可以发现,在相同的scrapy请求并发数情况下,利用更多的splash渲染服务能够明显地获得更高的抓取效率;但如果在拥有同样数量的splash服务时,单纯地去提高scrapy请求并发数,得到的抓取效率提升就显得相对有限,这很可能是因为整体的性能瓶颈此时已经不再是渲染需要的CPU利用率了,而是变成scrapy自身处理效率及整体网络通信的瓶颈。
splash的启动
splash既可以在程序里使用依赖docker.py进行启动,或者在命令行中人工启动。通过程序启动的示例如下:1
con = client.create_container(image="scrapinghub/splash", volumes=["/etc/splash/filters"], ports=[8050], host_config=client.create_host_config(port_bindings={8050:port_use}, binds=["/home/spider/Downloads:/etc/splash/filters"]))
其中参数image是该容器启动的映像名字;volume代表容器内部使用的挂载,其中的地址与外部文件无关,是定义在容器内一块文件;ports代表该容器会监听自己内部的8050端口,这是splash内部固定设置,不建议更改;host_config是建立主机和容器的一种绑定关系的设置,绑定包括两部分内容,一个是内部的8050端口和外部port_use端口的绑定,如果以后确定scrapy请求的端口号设置为8060,则将port_use设置为8060,另外一个是外部文件和容器内部挂载的绑定,冒号后面的目录是之前volumes的值,冒号之前的目录则填写你自定义过滤文件的目录,默认取名为default.txt,例如在后面会提到的请求过滤规则文件default.txt我们放在”/home/spider/Downloads”目录下,则像上述代码一样填写即可。
splash还有另外一种命令行人工启动的方法,需要敲入的命令是:1
[root@slave1 ~]# docker run -p 8053:8050 –v /home/spider/Downloads:/etc/splash/filters scrapinghub/splash
这里的-p后跟的8053代表主机提供scrapy的请求端口,8050仍然是docker容器内部定义的固定端口;-v仍然是对volumes的配置,冒号前为本机实际的文件目录,冒号后是容器内部的文件系统,不用更改;最后添加的scrapinghub/splash是容器要启动的映像名称。
splash的使用
在scrapy的setting.py文件中添加:
1
SPLASH_URL = 'http://192.168.0.1:8053'
在scrapy的setting.py文件中修改下载中间件的设置:
1
2
3
4
5DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}在scrapy的setting.py文件中添加去重中间件:
1
2
3SPIDER_MIDDLEWARES = {
'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}设置定制的去重类:
1
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
设置URL使用splash渲染服务:
1
2
3
4
5
6
7
8
9
10yield scrapy.Request(url, self.parse_result, meta={
'splash': {
'args': {
# set rendering arguments here
'html': 1,
},
'endpoint': 'render.json', # optional; default is render.json
'splash_url': '<url>', # optional; overrides SPLASH_URL
}
})
splash请求过滤文件
1 | ! customize |
上述代码列举了CSS文件,图片文件和部分广告链接等。将此文件改名为default.txt即可。
nginx负载均衡的配置和使用
安装nginx,只需要命令行使用yum install即可:
1
[root@slave1 ~]# yum install nginx
运行前修改配置文件/etc/nginx/nginx.conf,在http处添加:
1
2
3
4
5
6
7http {
upstream splash{
server 223.3.95.199:8051;
server 223.3.95.199:8052;
server 223.3.95.199:8053;
}
}再修改配置文件/etc/nginx/conf.d/default.conf:
1
2
3
4
5
6
7
8server {
listen 8050;
server_name mySplash;
location / {
proxy_pass http://splash;
}
}开启nginx进程:
1
[root@slave1 spider]# /usr/sbin/nginx
重启或关闭进程:
1
2[root@slave1 spider]# /usr/sbin/nginx –s reload
[root@slave1 spider]# /usr/sbin/nginx –s stop