推荐系统中NMF的一点看法
Created at 2017-01-12 Updated at 2017-08-18 Category ML
NMF(Non-negative Matrix Factorization),即非负矩阵分解,它可以简单定义为:给定矩阵$X∈R_+^{(n×m)}$,寻找非负矩阵$W∈R_+^{(n×k)}$和非负矩阵$H∈R_+^{(k×m)}$,使得$X≈WH$。其简单的直观表示如下图所示: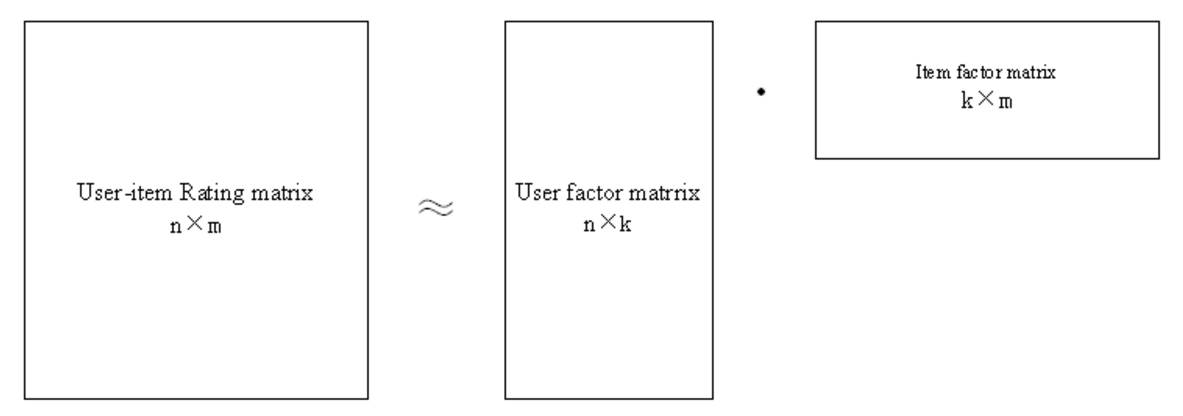
在计算中等式左右很难完全相等。在计算中往往是根据某更新法则迭代更新出两个乘子,当上式左右两端的距离(如欧式距离)满足我们设定的大小,停止迭代。它的目标很明确,就是将大矩阵分解成两个小矩阵,使得这两个小矩阵相乘后能够还原到大矩阵,而非负表示分解的矩阵都不包含负值。矩阵分解能够用于发现两种实体间的潜在特征,一个最常见的应用就是协同过滤中的预测打分值,即采用矩阵分解来进行用户推荐,而从协同过滤的这个角度来说,矩阵的非负性也很容易理解:用户打分都是正的,不会出现负值。
在例如MovieLens这样的推荐系统中,有用户和电影两个集合。给出每个用户对部分电影的打分,我们希望预测该用户对其他没看过电影的打分值,这样可以根据打分值为其做出推荐。用户和电影的关系,可以用一个矩阵来表示,每一行表示用户,每一列表示电影,每个元素的值表示用户(User)对已经看过的电影(Item)的打分(1-5分),矩阵形如下表,表中的 – 代表该用户未对此电影打分:![]()
在对上述矩阵进行矩阵分解时,我们希望得到如下图的矩阵乘积,为方便理解和之后的可视化操作,我们假设特征(Feature)的数量K为2: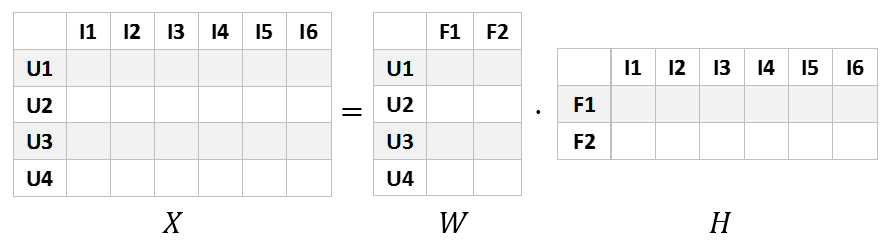
图中$X$为原始的评分矩阵,$W$为用户对特征的偏好程度矩阵,$H$为电影对特征的拥有程度矩阵。$W$的每一行表示用户,每一列表示一个特征,它们的值表示用户与某一特征的相关性,值越大,表明特征越明显。同理,$H$的每一行表示电影,每一列表示电影与特征的关联。最后为了预测用户算$U_i$对特定电影$I_j$的评分,我们可以直接计算$U_i$和$I_j$对应的特征向量的点积。
使用矩阵分解来预测评分的思想来源于,我们可以通过矩阵分解来发现一些用户打分的潜在特征。比如两个人都喜欢某一演员,那他们就倾向于给TA演的电影打高分;或者两个人都喜欢动作片,则他们会偏向给动作片好评。假如我们能够发现这些特征,我们就能够预测特定用户对特定电影的打分。通常情况下,我们假设特征的数量少于用户和电影的数量,但同时也必须保证不能过少或过多,否则会陷入欠拟合和过拟合的情况。
接下来是我有些不解的地方:在实际生活中,我们有时很难拿到用户所有的打分值,所以得到的用户评分是一个非常稀疏的矩阵。由于NMF分解是对原矩阵的近似还原分解,所以该算法会尽力去拟合原矩阵中的大量的零值点,这对于其他项目的评分预测都是相当不准确的。所以我想尝试利用梯度下降的方法,只去拟合那些非零值,以期可以忽略零值对分解结果的影响。
目标函数
误差函数
$$error=\sum\limits_{i,j}^{X_{ij}>0} [X_{ij}-(WH)_{ij}]^2$$
计算预测评分与原始评分之差的平方和,并将之作为误差函数进行最优化,其中的计算项只包括原始评分不为零的评分项。正则化项
$$reg=β(‖W‖^2+‖H‖^2)$$
上式中,$β$为权重,$‖W‖^2$和$‖H‖^2$分别为矩阵$W$和$H$的L2范数,即矩阵中所有元素的平方和。目标函数
$$T(W,H)=\sum\limits_{i,j}^{X_{ij}>0} [X_{ij}-(WH)_{ij}]^2+β(‖W‖^2+‖H‖^2)$$
梯度下降
计算偏导
$$\frac{∂T(W,H)}{∂W_{ik}}=-\sum\limits_{i,j}^{X_{ij}>0} \sum\limits_k 2(X_{ij}-(WH)_{ij})H_{kj}+2βW_{ik}$$
$$\frac{∂T(W,H)}{∂H_{kj}}=-\sum\limits_{i,j}^{X_{ij}>0} \sum\limits_k 2(X_{ij}-(WH)_{ij})W_{ik}+2βH_{kj}$$
上式中,我只考虑原始矩阵中的非零元素,因为其中的零值只代表用户未对电影做出评分,并不代表该用户对此电影的评分就是0,所以我们在计算时不对零值进行拟合。迭代更新
$$W_{ik}=W_{ik}+α(\sum\limits_{i,j}^{X_{ij}>0} \sum\limits_k (X_{ij}-(WH)_{ij})H_{kj}-βW_{ik})$$
$$H_{kj}=H_{kj}+α(\sum\limits_{i,j}^{X_{ij}>0} \sum\limits_k (X_{ij}-(WH)_{ij})W_{ik}-βH_{kj})$$
其中,$α$是学习速率,即每次前进的步长,$α$越大,迭代下降的越快。上式中,我们将因子2提取出来计入$α$,简化表达式。
非负性保证
传统NMF中,如非负矩阵分解(NMF)中所示的高斯分布噪声下,可以转化为矩阵乘法的迭代,从而保证非负性。而这里情况就不同,我没有依据地自创了两个条件保证非负性。
$W$与$H$的初始化
随机初始化时保证所有元素均为非负数,则能够在后续迭代中提供一个很好的非负性保证。
事实上,$W$与$H$的结果对初始状态是非常敏感的。我在实现时参考了sklearn里nmf采用的一种基于svd分解的初始化方法。学习速率递减
在$W_{ik}$或者$H_{kj}$在梯度下降时,如果某个元素值即将发生由非负到负的转变时,我们将学习速率自动减半,重新进行迭代计算,如果仍然产生负值,则重复上述步骤,当学习速率减半操作次数达到一定阈值时,我们则判定该元素无法继续进行迭代,保持原来的数值不变。
这点没有什么理论支撑,纯属自己臆想。
推荐应用
假设有如下所示的用户对电影的评分矩阵: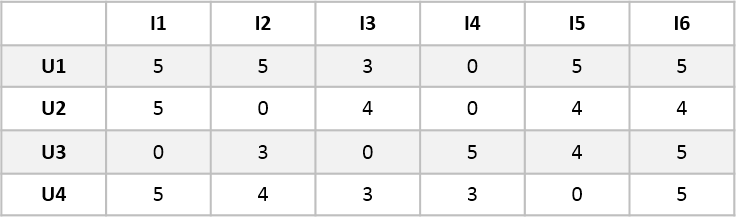
对其做非负矩阵分解,可得$W$矩阵和$H$矩阵: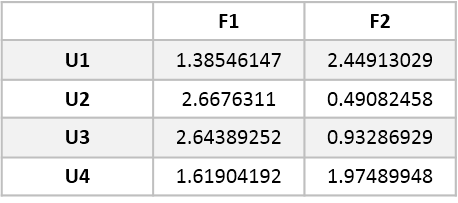

我们将$W$和$H$矩阵相乘,可以重构还原得到如下矩阵: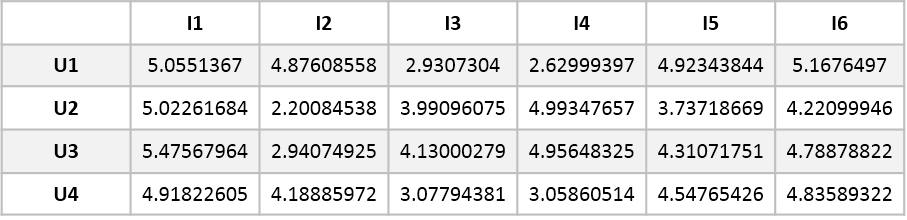
可以看到,重构还原后的矩阵$V$跟原矩阵$X$很接近,并且对原来空缺的值作出了预测。我们在这些结果的基础上,通过计算用户间或电影间的相似度,进行一些推荐的应用,可以参考博客矩阵分解在推荐系统中的应用:NMF和经典SVD实战。
与SVD和NMF的对比
相关代码上传至Github,附上链接,很杂乱。
我使用了MovieLens推荐系统的公开100K实验数据集,为了比较本文算法在评分较少的稀疏矩阵中的效果,实验中选取了已看电影不超过100部的观众,根据其对一些电影的评价来预测对其他部分电影的评分。训练集中选取了655个人对1342部电影的评分,分数仅限1,2,3,4,5这五种打分,测试数据集是对应观众对其他部分电影的评分。
实验采用的算法除了本文的稀疏矩阵分解(Sparse NMF),还有现有的奇异值矩阵分解法(SVD)和非负矩阵分解法(NMF),以及评分全为3分的平均值矩阵(Average)来做比较。算法的预测评分中,小于1分的将被划为1,大于5分的将被划为5。实验中采用的误差评价为测试集中有效评分与算法预测评分差的平方和,公式表示如下:
$$error=\sum\limits_{i,j}^{X_{ij}>0} [X_{ij}-V_{ij}]^2$$
上式中$X_{ij}$表示用户$i$对电影$j$的实际评分,$V_{ij}$表示用户$i$对电影$j$的预测评分。实验得到的结果对比如下图: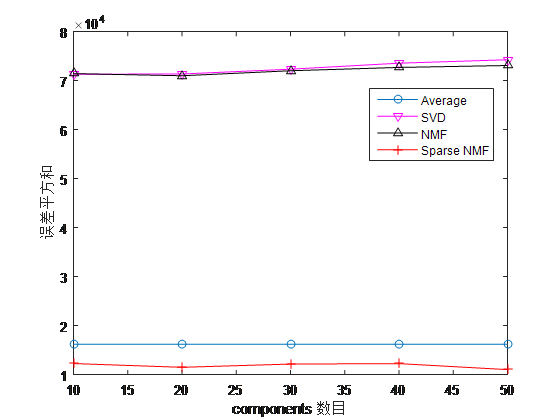
上图中的横坐标components数目是上面提到的特征数量K。
由于SVD矩阵分解和NMF分解都是对原矩阵的近似还原分解,所以这两种算法会尽力去拟合原矩阵中的大量的零值点,这对于其他电影的评分预测都是相当不准确的。他们的性能甚至比平均值猜测都差很多,所以在稀疏的评分矩阵中,SVD矩阵分解和NMF分解都是不太合适的。而本文的Sparse NMF误差大约为平均值的70%,有一定的效果,但仍有很大的改善空间。
吐槽:
- 我这种一个元素一个元素计算的方法效率很低,没考虑优化的问题。
- 我还试过另外一种方法,将所有空缺值用所有其他非零项平均值填补,之后再使用SVD或者NMF,效果比不填补使用Sparse NMF要好,填补再用Sparse NMF我也没试过。
以上均为本小白个人理解,如有任何不当或者错误,欢迎指正。
本文有参考以下博文: