CentOS下使用Graphite监测scrapy
Created at 2016-10-06 Updated at 2018-05-12 Category Crawler
受github上一个前人的爬虫项目的指导,我学习了里面使用Graphite监控的部分,在这篇博客里把我在安装和使用中遇到的问题全部记录下来。
Graphite简介
Graphite是一个Python编写的企业级开源监控工具,采用django框架,用来收集服务器所有的即时状态,用户请求信息,Memcached命中率,RabbitMQ消息服务器的状态,操作系统的负载状态。Graphite服务器大约每分钟需要有4800次的跟新操作,它采用简单的文本协议和绘图功能,可以方便的使用在任何操作系统上。Graphite自己本身并不收集具体的数据,这些数据收集的具体工作通常由第三方工具或插件完成(如 Ganglia, collectd, statsd, Collectl 等)。
简单来说,Graphite主要做两件事情:
- 实时监控第三方工具传来的数据
- 根据数据绘制图形
Graphite包含3个组件,carbon,whisper,graphite webapp其中:
- carbon - 用于监控数据的 Twisted 守护进程
- whisper - 用于存放和操作数据的库
- graphite webapp - 用于绘制图形的Django webapp
关于Graphite的详细官方文档可以参考Graphite Documentation。
Graphite安装
Graphite的安装,我更多地参考了这一篇博客用graphite diamond做监控。
首先,我的安装环境是CentOS 6.6,Python2.7.10。
在python等开发环境都安装OK之后,我们使用pip安装Graphite的三个组件:1
2
3pip install whisper
pip install carbon
pip install graphite-web
这样的方法会将它们安装在默认路径/opt/graphite下。安装完成后,你会发现/opt/graphite下多了一堆东西,将/opt/graphite/conf下的*.example,拷贝到去掉example即可。
启动carbon,carbon会在默认的2003端口接收数据。1
python /opt/graphite/bin/carbon-cache.py start
启动django,即整个Graphite的web应用。1
python /opt/graphite/webapp/graphite/manage.py runserver 0.0.0.0:12222
其中的12222号端口可以自己任意修改。
这样浏览器打开http://127.0.0.1:12222就可以看到Graphite的界面。
然而启动django这一步我在运行的时候遇到了各种错误。
- 在我
pip install的django最新版本为2.0的时候,我遇到了大量有关pattern的错误,我按照网上说的全部更改之后还是无法运行,所以弃掉2.0。 然而我
pip install django==1.9之后,还是遇到了- no such table: auth_user
- no such table: account_profile
- Unknown command: ‘syncdb’
这三种错误,发生的先后顺序不一定准,但我在疯狂查阅各种资料之后还是没有成功解决。
- 这些错误都是因为django版本不兼容导致的,在我
pip install django==1.8之后,整个世界就清静了。
如果这时候以为打开浏览器就能看到界面的话,那你还是太年轻了。命令行能够运行没错,但是web可视化的界面还是有错!
Graphite界面会提示import cairo出错,这个cairo也是个大坑,原因就是你没有安装cairo图形库,pip install cairo之后你终于能松一口气欣赏一下Graphite了。
页面右上角的dashboard页面可以玩一下,有很多高阶的功能,你会看到左侧tree那边有一些数据,这些数据存储在/opt/graphite/storage/whisper。
另外,Graphite有个时区设置的问题,如果不更改,你的时间显示都是GMT时间。只需将/opt/graphite/webapp/graphite/local_settings.py文件里的TIME_ZONE配置改成如下:1
2
3
4# Set your local timezone (Django's default is America/Chicago)
# If your graphs appear to be offset by a couple hours then this probably
# needs to be explicitly set to your local timezone.
TIME_ZONE = 'Asia/Shanghai'
如果之后想对Graphite的详细架构和具体配置有更深入的了解的话,推荐两个链接:
Graphite与scrapy的结合
结合的方法详见原作者项目中graphite.py文件中的注释,我总结为一下几点:
- 把
/opt/graphite/webapp/content/js/composer_widgets.js文件中toggleAutoRefresh函数里的interval变量从60改为1。 在配置文件
storage-aggregation.conf里添加1
2
3
4
5
6
7
8
9
10
11
12[scrapy_min]
pattern = ^scrapy\..*_min$
xFilesFactor = 0.1
aggregationMethod = min
[scrapy_max]
pattern = ^scrapy\..*_max$
xFilesFactor = 0.1
aggregationMethod = max
[scrapy_sum]
pattern = ^scrapy\..*_count$
xFilesFactor = 0.1
aggregationMethod = sum在爬虫的配置文件
setting.py里添加1
2
3STATS_CLASS = 'scrapygraphite.GraphiteStatsCollector'
GRAPHITE_HOST = '127.0.0.1'
GRAPHITE_PORT = 2003后两点是我自己的修改。
scrapy本身提供的状态记录偏少,且缺乏实时的速度信息,都是不断增长式的总和记录。我想让scrapy能够定时发送pages的抓取速度和item的生成速度给Graphite,所以我在scrapy源码的scrapy/extensions/logstats.py文件中添加了两个状态变量的发送。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27def spider_opened(self, spider):
self.pagesprev = 0
self.itemsprev = 0
self.task = task.LoopingCall(self.log, spider)
self.task.start(self.interval)
self.stats.set_value('pages_min', 0, spider=spider)
self.stats.set_value('items_min', 0, spider=spider)
def log(self, spider):
items = self.stats.get_value('item_scraped_count', 0)
pages = self.stats.get_value('response_received_count', 0)
irate = (items - self.itemsprev) * self.multiplier
prate = (pages - self.pagesprev) * self.multiplier
self.pagesprev, self.itemsprev = pages, items
msg = ("Crawled %(pages)d pages (at %(pagerate)d pages/min), "
"scraped %(items)d items (at %(itemrate)d items/min)")
log_args = {'pages': pages, 'pagerate': prate,
'items': items, 'itemrate': irate}
logger.info(msg, log_args, extra={'spider': spider})
self.stats.set_value('pages_min', prate, spider=spider)
self.stats.set_value('items_min', irate, spider=spider)
states = self.stats.get_stats()
for key in states:
self.stats._set_value(key, states[key], spider=spider)这里的log函数每隔interval的秒数就会执行一次,interval的值可以在setting里配置
LOGSTATS_INTERVAL的值。因为scrapy里的状态值很多是在增长时才会调用inc_value去加一改变大小,数据不增长就不会变,也不会去发送给Graphite。所以我在定时执行的log函数里强行再去发送一下数据,不管值有没有改变,即最后的三行代码。虽然我感觉在Graphite的显示里这样做好像并没有什么效果。在数据的分布定义storage-schemas.conf中,默认是按60秒一个数据的方式,存一天的数据,一天前的数据就没了。
1
2
3[default_1min_for_1day]
pattern = .*
retentions = 60s:1d但是爬虫的数据60s存一个数据显得有点稀疏,特别是在想要显示实时抓取速度时候,这里可以根据不同需求进行更改。
最后
贴一个Graphite的效果图: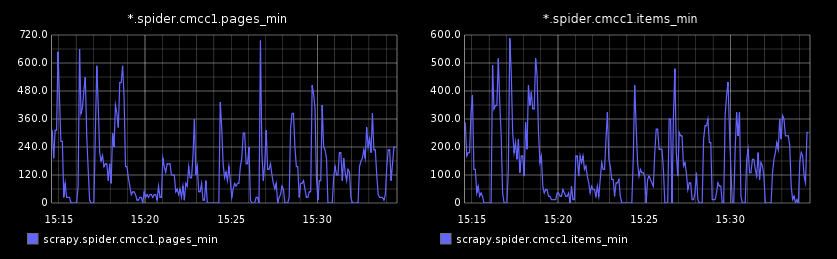
如果嫌原版Graphite界面丑,据说可以使用豆瓣写的皮肤graph-index。