NLP中使用HMM进行tag、seg和ner
Created at 2016-07-28 Updated at 2016-09-02 Category NLP
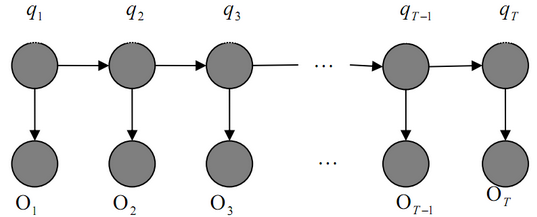
看到网上有很多分词、词性标注的工具,但大多是已经训练过的模型,有些可以添加一些自定义的词典来定制模型。趁同学给了我一些nlp的中文语料数据,我就尝试自己实现一个简单的HMM(隐马尔科夫模型)来进行中文的词性标注(Part-of-Speech tagging或POS tagging,以下简称tag)、分词(Segmentation,以下简称seg)和命名实体识别(Named Entity Recognition,以下简称ner)。
具体关于HMM的内容,这篇博文里面不做赘述,读者可以自行学习了解,也可以参考本人之前的一篇博文HMM、MEMM和CRF的学习总结和里面提供的一些链接。
代码相关
整个HMM的代码和相关测试数据已上传至Github上,附上链接。整个代码的实现有部分学习参考博客python词法分析(分词+词性标注),感谢博主的分享。
文件图如下:
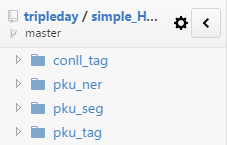
这四个文件夹中都是用的是同一个HMM模型,只是测试数据和目标任务不同而已。其中tag相关的有两个:conll_tag和pku_tag,conll_tag使用的CoNLL-2000的英文数据,具体数据下载见Chunking,pku_tag使用的一个北大同学给的课程作业的中文语料数据。pku_seg和pku_ner同理分别是在相应的数据上进行的分词和命名实体识别。其实,seg和ner的实现依赖于tag的词性标注,只是seg、ner要学习的的标签不同。整个HMM的实现也中规中矩,从语料数据中学习转移概率、发射概率等等,然后利用viterbi算法求解最大路径。其中在计算路径概率的时候,为了防止概率相乘过小约等于零的情况,程序取概率对数再取反,将概率相乘转化为对数相加。
tag
数据说明
tag这里指语句的词性标注,当然不同的语料采用的词性体系不太相同。- conll2000为英文语料,给出的数据一共有三列,每一列代表的含义在上面给出的链接里有提及。第一列是英文单词本身,第二列是由Brill tagger标注的词性,第三列是华尔街日报语料库产生的标注,其实第三列的标注和分词的标注方法类似。
- pku的数据是中文语料,且已经进行过分词操作,它的词性标注与近代汉语词类标注简表相似但不完全相同。
测试结果
关于准确率,程序将数据七三分做交叉验证来计算。conll2000对第二列的Brill tagger的准确率约为94.09%,对第三列的WSJ corpus的准确率约为87.93%。pku的准确率约为93.0%。结果分析
- 本文实现的HMM对实际详细的词性标注如conll的Brill tagger和pku的标注有较好的效果,而conll的WSJ corpus的标注偏向语句的分词,效果会差一些。
- 我实现的HMM在训练完进行标注的时候,没有去检测一些数字,日期等等的存在,而是单纯地看它在不在训练集里,比如之前训练时统计到过6.11是数字,但没见过6.12,那之后就标注不出来了。这是很大一块需要改进的地方。
seg
处理思路
seg的处理思路就是将训练数据转化为上一项tag(POS Tagging)所需的训练数据格式,程序里我采用的是4-tag(B(Begin,词首), E(End,词尾), M(Middle,词中), S(Single,单字词))标记集。这里转化来转化去的脚本需要自己写。关于这种标记方法和转化过程的详细介绍可以参考这篇中文分词入门之字标注法3。测试结果
对pku的数据测试得到的准确率为92.13%,召回率为91.88%,F1值为92.01%。
ner
数据说明
ner的训练数据里,非命名实体的都标注为N,“北京市”中“北”标为“B-LOC”,代表为地名的开始,“京”和“市”跟在后面则标为“I-LOC”。在最后计算准确率和召回率的时候,标为“N”的字都不需要考虑,仅看那些命名实体是否被标注出来。测试结果
对pku的数据测试得到的准确率为67.6%,召回率为63.9%,F1值为65.7%。结果分析
从结果可以看出,在不使用规则或字典等其他方法干预的情况下,单纯使用HMM对命名实体识别效果较差。